【python 中级】 算法 题目记录
本文章记录了有关 python 数据处理 题目 和 排序 查找 案例 的汇总。
# 【python 中级】 算法 题目记录
*python 技术栏*
本文章记录了有关 python 数据处理 题目 和 排序 查找 案例 的汇总。
## 目录
[TOC]

## 排序操作
### 冒泡排序
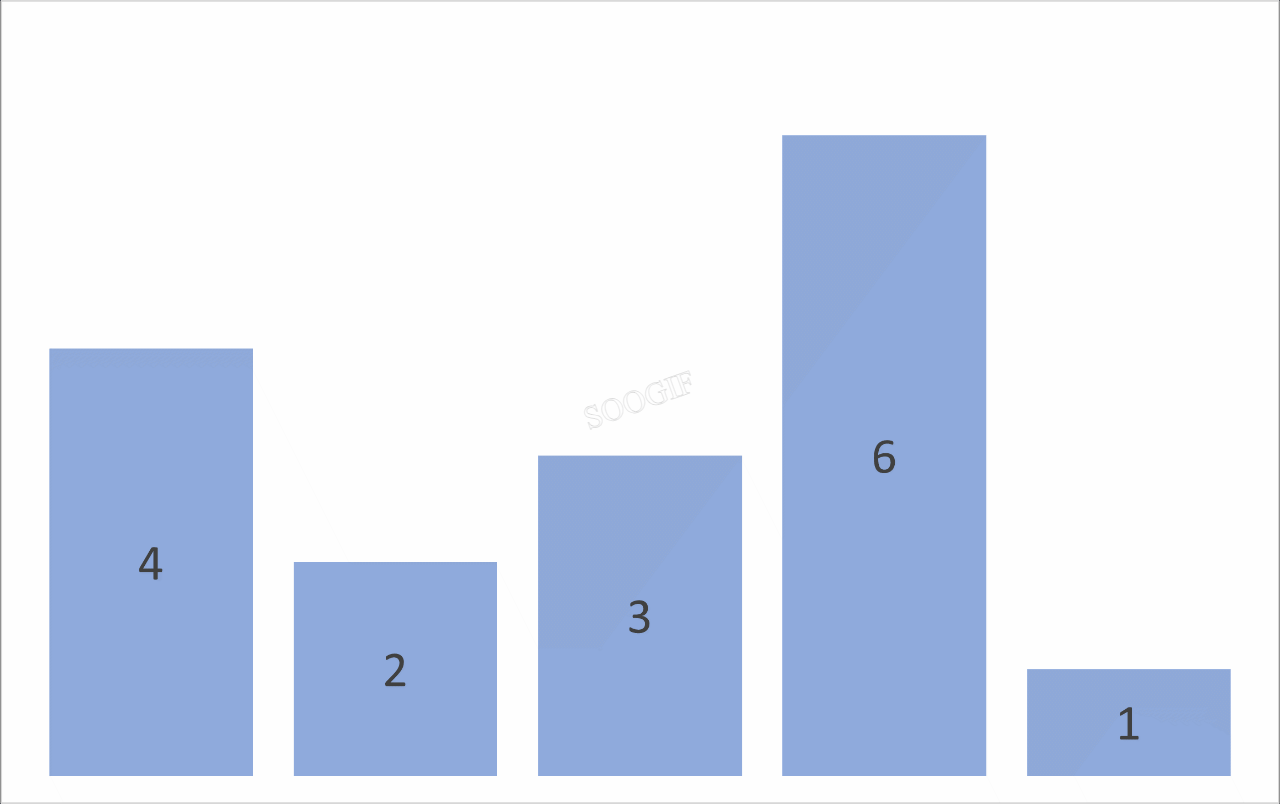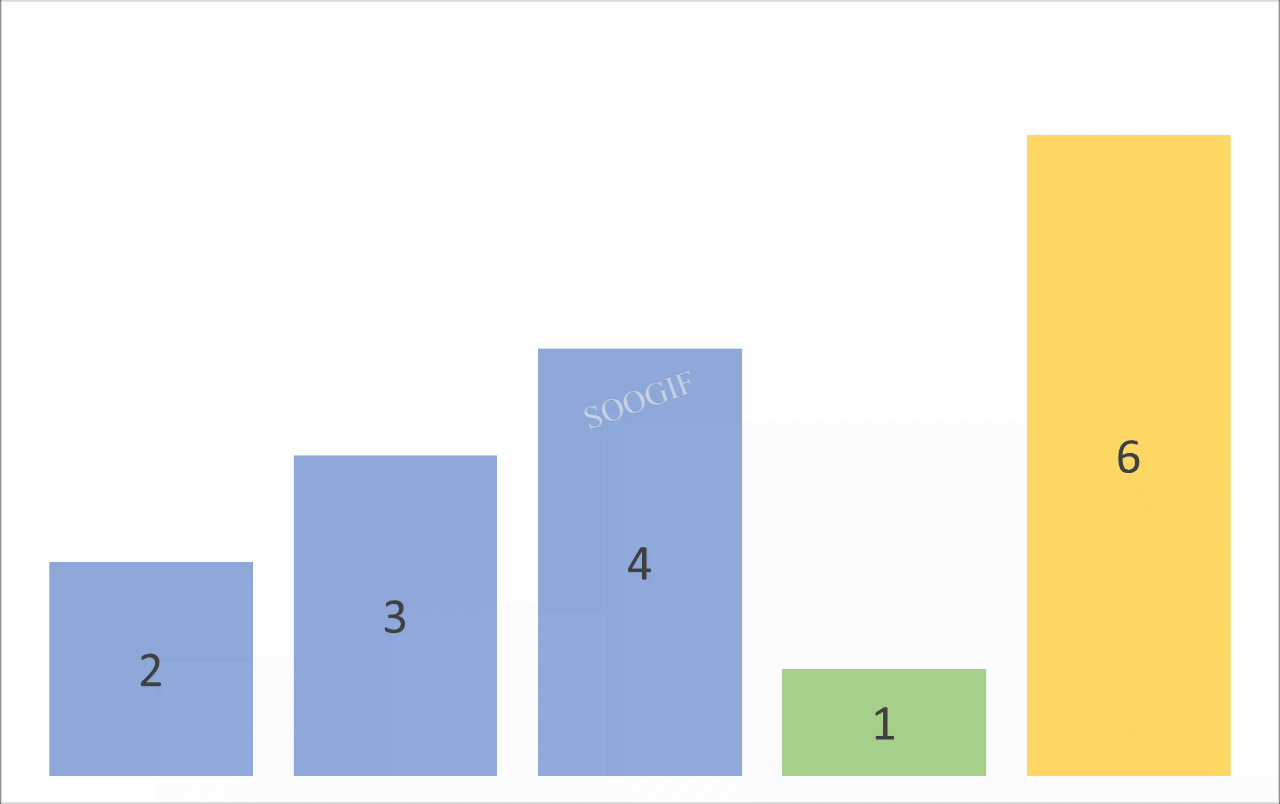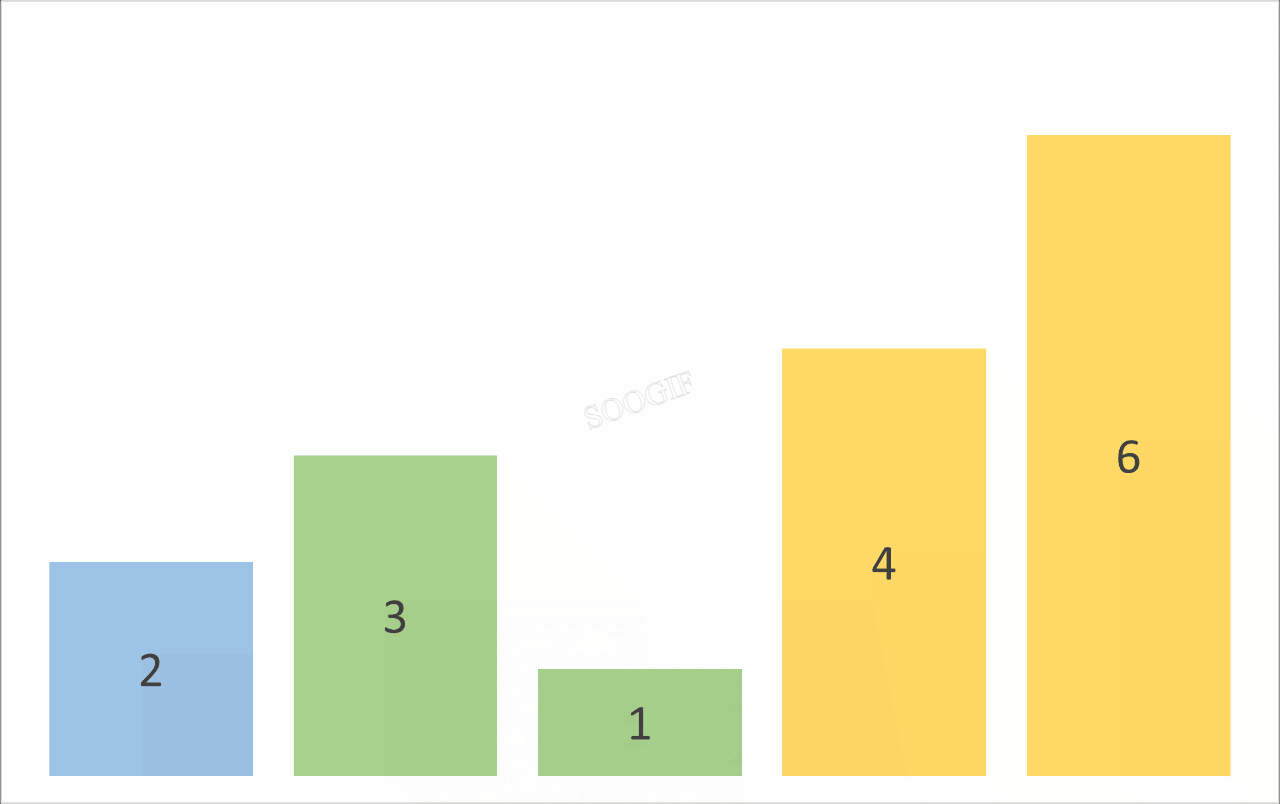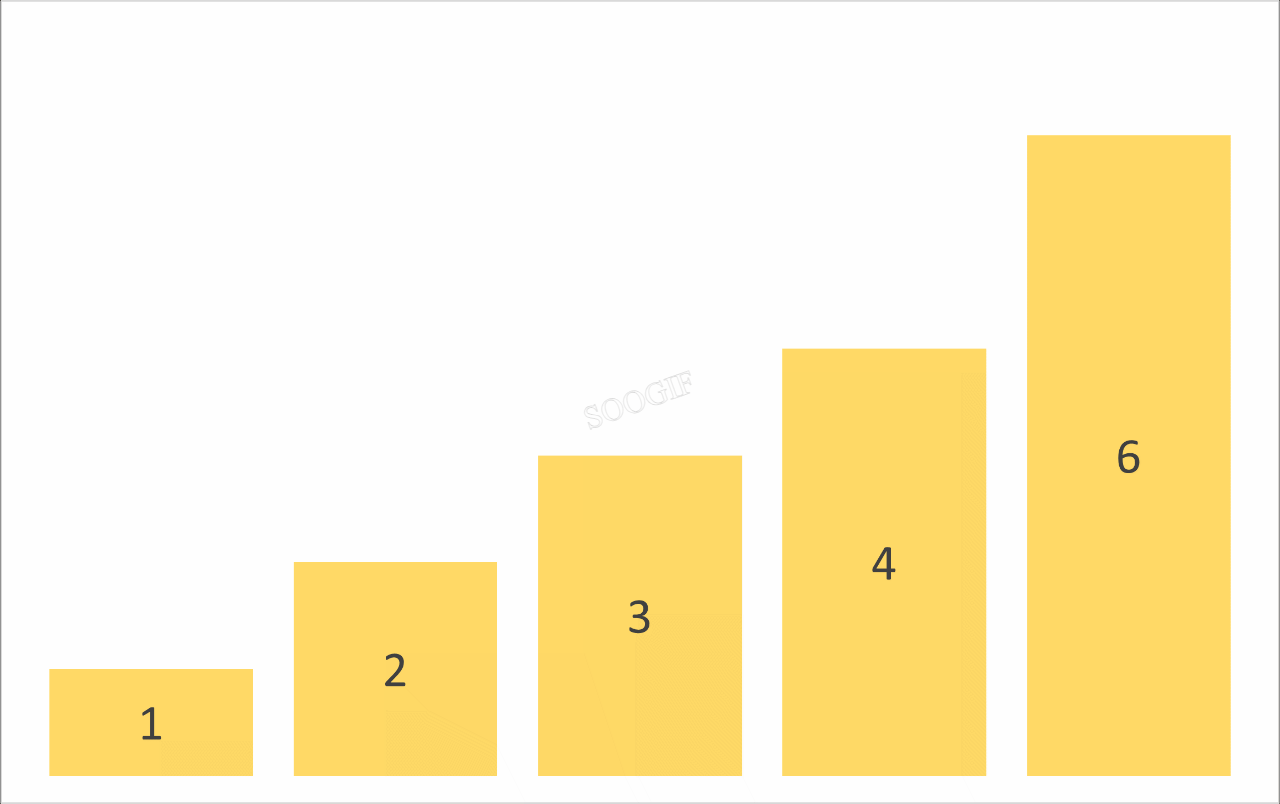
冒泡排序是一种简单的排序算法,它重复地遍历要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。遍历数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
```
def sort(arr: list[int]):
# 在冒泡排序中 每一次循环都会将一个数值放到合适的位置
# 例如 3 1 2 0 第一次冒泡之后 结果是 1 2 0 3
# 因此列表中有几个数值 就需要有几次冒泡
for index in range(0, len(arr)):
# 在每次的冒泡中 我们的任务其实就是将相邻的两个元素两两比较
for i in range(0, len(arr) - index - 1):
# 最终我们可以将最小或最大的放到前面
if arr[i] > arr[i + 1]:
arr[i], arr[i + 1] = arr[i + 1], arr[i]
print(f"第{index + 1}次冒泡结果 = {arr}")
if __name__ == '__main__':
d = [3, 1, 2, 0]
sort(d)
print(d)
```
### 选择排序
选择排序算法的工作原理是首先在未排序序列中找到最小(或最大)元素,存放到排序序列的起始位置,然后再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
```
def sort(arr: list[int]):
for index in range(0, len(arr)):
# 获取到当前已排序的数据中 最大的数值
max_num = arr[index]
# 使用循环 将最大数值后面未排序的值进行依次比较,将比 max 更小的值与 max 位置互换
# 因为小的要在前面 所以 max 变为更小的
for i in range(index + 1, len(arr)):
if arr[i] < max_num:
# 说明 arr[i] 比 max 更适合前面的位置 在这里进行交换位置
arr[index], arr[i] = arr[i], arr[index]
# 不要忘记更新这个值
max_num = arr[index]
print(f"第{index + 1}次选择,已排序位置为{index}:结果 = {arr}")
if __name__ == '__main__':
d = [3, 1, 2, 0]
sort(d)
print(d)
```
### 插入排序
插入排序的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,通常采用in-place排序(即只需用到`O(1)`的额外空间的排序),因此它是稳定的。
```
def sort(arr: list[int]):
# 第一层循环其实就是标记 标记被排好序的元素
for index in range(1, len(arr)):
# 在这个循环中 我们只需要找到当前元素 并将下一个元素在已排序范围中找到合适的插入位置
for i in range(index, 0, -1):
# 在这个循环中 我们需要找到当前元素在当前以及前面所有元素的最佳位置
now_num = arr[i]
# 在这里进行比较 如果 now_num 的值更大 则需要将 now_num 值与已排序的值进行位置互换 直到找到合适的位置
if now_num < arr[i - 1]:
# 需要换位置
arr[i - 1], arr[i] = arr[i], arr[i - 1]
else:
# 代表找到合适位置了 前面不需要继续搜索了 直接结束
break
print(f"第{index}次插入,已排序位置为{index}:结果 = {arr}")
if __name__ == '__main__':
d = [3, 1, 2, 0, -1024]
sort(d)
print(d)
```
### 快速排序
快速排序是由东尼·霍尔所发展的一种排序算法。在平均状况下,排序 n 个项目要 Ο(nlogn) 次比较。在最坏状况下则需要 Ο(n2) 次比较,但这种状况并不常见。事实上,快速排序通常明显比其他 Ο(nlogn) 算法更快,因为它的内部循环(inner loop)可以在大部分的架构上很有效率地被实现出来。
快速排序使用分治法(Divide and conquer)策略来把一个串行(list)分为两个子串行(sub-lists)。
快速排序又是一种分而治之思想在排序算法上的典型应用。本质上来看,快速排序应该算是在冒泡排序基础上的递归分治法。
> 它的步骤如下
① 从数列中挑出一个元素,称为 “基准”(pivot);
② 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
③ 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序;
递归的最底部情形,是数列的大小是零或一,也就是永远都已经被排序好了。虽然一直递归下去,但是这个算法总会退出,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。
```
def sort(arr: list[int]):
if len(arr) <= 1:
# 代表不需要排序了
return
elif len(arr) == 2:
# 直接交换下位置就行
if arr[0] > arr[1]:
arr[0], arr[1] = arr[1], arr[0]
print(f"最终排序:{arr}")
return
# 快速排序有两个步骤 一个是分区 一个是合并
# 分区的操作就是将比基准值小的区域和比基准值大的区域划分开 下面就是分区操作
pivot = arr[0]
# 使用循环创建两个列表 分别是比基准值小的和比基准值大的
l, r = [], []
for n in arr:
if n < pivot:
l.append(n)
else:
r.append(n)
print(f"基准值{pivot},待排序 = {l}, and {r}")
# 然后我们再让两个列表进行快速排序
sort(l)
sort(r)
# 写回结果
arr.clear()
arr.extend(l + r)
if __name__ == '__main__':
d = [3, 1, 2, 0, -1024]
sort(d)
print(d)
```
### 归并排序
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
```
# 用来存储临时结果!
r = []
def sort_fun(arr: list[int], low: int, high: int):
if low >= high:
# 代表排序结束了
return
# 获取到基准值索引
midIndex = low + ((high - low) >> 1)
# 排序 将左右部分排序
sort_fun(arr, low, midIndex)
sort_fun(arr, midIndex + 1, high)
print(f"排序之后 = {arr}")
# 准备两个标
l_index, r_index = low, midIndex + 1
r.clear()
# 开始进行合并 合并的逻辑是 l_index r_index 两个指针的值依次对比 按照大小顺序依次追加数据并移动指针
while l_index <= midIndex and r_index <= high:
# 将更小的追加到新的数组中
if arr[l_index] < arr[r_index]:
r.append(arr[l_index])
l_index += 1
else:
r.append(arr[r_index])
r_index += 1
# 将剩余的追加下
while l_index <= midIndex:
r.append(arr[l_index])
l_index += 1
while r_index <= high:
r.append(arr[r_index])
r_index += 1
# 将操作结束的结果写到 arr 里
l_index = low
for n in r:
arr[l_index] = n
l_index += 1
if l_index >= len(arr):
break
print(f"合并之后 = {arr}")
def sort(arr: list[int]):
sort_fun(arr, 0, len(arr) - 1)
if __name__ == '__main__':
d = [3, 1, 2, 0, -1024]
sort(d)
print(d)
```
## 查找操作
### 二分查找
```
def search(nums: list[int], target: int) -> int:
# 准备两个指针 代表查找的区间
l, r = 0, len(nums) - 1
while l <= r:
# 获取到当前中间值
midIndex = (l + r) // 2
midValue = nums[midIndex]
# 开始比较
if target < midValue:
# 舍弃右区间
r = midIndex - 1
elif target > midValue:
# 舍弃左区间
l = midIndex + 1
else:
# 区间中只剩下了一个元素 左右边界都指向这个数值了 就代表存在
return midIndex
# 如果区间的边界相互越过 说明没查找到元素
return -1
if __name__ == '__main__':
d = [1, 2, 3, 4, 5, 6, 7, 8, 9, 1024]
print(search(d, 2))
print(search(d, 9))
```
------
***操作记录***
作者:[python](https://www.lingyuzhao.top//index.html?search=33 "python")
操作时间:2024-07-04 14:10:30 星期四
事件描述备注:保存/发布
中国 天津
[](如果不需要此记录可以手动删除,每次保存都会自动的追加记录)